Clustering is a mode of replication between two nodes to implement fault tolerance to your system. This schema implements a highly available (HA) environment, providing a continued level of service over a period of time.
Vocera Platform is focused on supplying a system for the delivery of contextual alerts and alarms without any downtime. The database (DB) and voice clustering features provide high availability to support your system in the event of a hardware or software failure.
In the event of a failure, the system must be able to recover and continue to process information. Vocera Platform uses an active-standby high availability (HA) model to continue processing information. In an active-standby HA model, all data on the active node is replicated to the standby node, allowing the standby node to remain synchronized and ready to transition to the active role. When failover occurs, the new active node takes over the Virtual IP (VIP) address assigned to the cluster, switches the database out of replication mode, and activates all adapters.
In Vocera Platform a cluster maintains a virtual IP address (VIP) that acts like a cluster-manager. The VIP is always assigned to the active node. All external traffic is targeted at the VIP and routed to the active node, automatically.
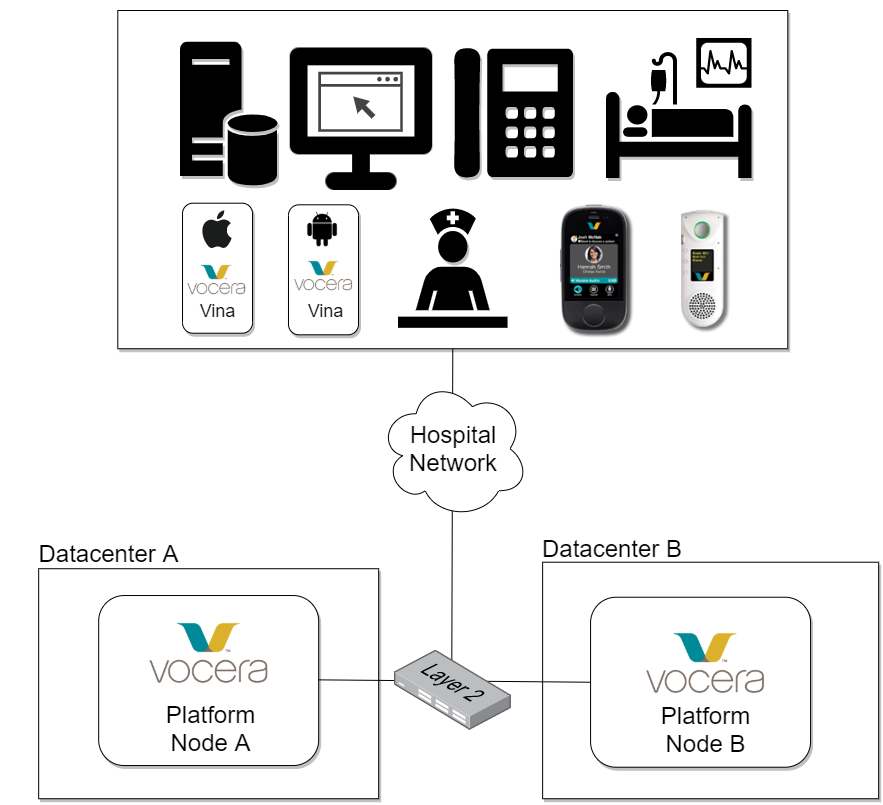
In this diagram, the hospital's services are supported by a highly available Vocera Platform cluster composed of two nodes (A and B) in separate datacenters. Should the active node in this cluster fail, the system will automatically transfer the VIP to the standby node and continue processing data without interruption.
Before configuring a node for clustering, you must choose whether to create a new cluster or to join an existing cluster. If you are creating a new cluster, then that node becomes the active node of that cluster. If you are joining a node to an existing cluster, then that node becomes a standby in that cluster.
Once two servers are joined in a cluster, the management of the cluster, data replication, and failover transitions are performed automatically without the need for manual user intervention. The active node exclusively responds to all service requests from the integrated systems. To maintain data coherency between the nodes, the active node replicates its database and file system information across to the standby node in real time.
The active node of a cluster sends out heartbeat messages to announce its presence to the standby node in the cluster. If a standby node fails to receive any heartbeat messages within a predefined time interval (default is 15 seconds), then it promotes itself to become the active node of the cluster.
An external application delivery controller (ADC), can also be employed to manage the cluster's VIP. When an external ADC is used, it maintains the IP address to which all the external traffic is targeted and routes the traffic to the active node. For more information on choosing between a cluster-manager VIP configuration or using an external ADC to manage the clusters, refer to HA Deployment Configuration Selection.