Configure the parameters of the Spark pipeline file.
The following figure shows the configuration of a Vocera Voice Server pipeline.
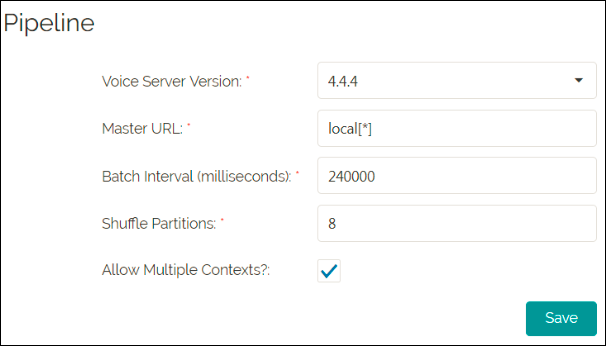
To configure a pipeline:
- Provide the required information as outlined in the following table.
Field Description Action Voice Server Version * Specifies the Voice Server version that you have configured. Note: Ensure that you select the correct version of the Voice Server you configured to parse the data accurately.Select a value. Master URL * Indicates the master URL passed to Spark. Local[*] implies to run Spark locally with as many worker threads as logical cores on your system. The value displayed is local[*] by default. Enter the master URL. Batch Interval (milliseconds) * Specifies the Spark micro batch interval. Spark streaming receives live input data streams and divides the data into batches. It is then processed by the Spark engine to generate the final stream of results in batches. The value displayed is 240000 by default. Enter a value. Shuffle Partitions * Specifies the number of partitions involved in the shuffle. It is the measure of parallelism during aggregate operations such as Join. The value displayed by default is 8. Enter a value. Allow Multiple Contexts? Indicates that Spark allows the creation of multiple streaming contexts. Check the box to allow multiple contexts. Note: Fields marked with an asterisk (*) are mandatory. - Click Save.
Saves your entries.
- Click ➜ Analytics Database.
The Analytics Database configuration page appears.