Adapters uses regular expressions (Regex) when parsing incoming messages for storage in a designated dataset in the Data Manager. This page contains an explanation of Regex, describes methods to specify Regex mappings, and provides a quick reference table of operators.
Incoming message data is processed in order to store information from a nurse call system and may later be used by the Workflow Engine to display a message on the end user's device. For example, the Vocera NaviCare Adapter uses Regex mappings configured in the Message Type settings to capture alert data sent by the NaviCare nurse call system.
This document will discuss Literal Expressions, Statements of Equality, and Global Variables.
General Guideline for Regular Expressions
When building a Regex for a facility, be sure to keep the expression as simple as possible while still meeting the needs of the facility. Performance issues, including delays in Alerts, can occur when overly complex Regex strings are written.
The system enforces a maximum processing time limit of five seconds to ensure that CPU loads are not significantly increased by overcomplicated Regex strings. A string that exceeds the threshold will generate an audit event and will not match any results.
For example, preprocessing rules might contain inefficient Regex with nested ungreedy matchers such as (.*?) that result in excess load on the system.
Below is an example of inefficient Regex for a preprocessor rule:
| (OBR(\|.*?){7}.?)(\d){4}(\d){2}(\d){2}(\d){2}(\d){2} |
This example could be expressed more efficiently as the following:
| "OBR(\|.*){7}.*?(\d){4}(\d){2}(\d){2}(\d){2}(\d){2}(\d){2}" |
Literal Expressions
Regex describes a search pattern, similar to the way *.txt is used to find text files in a file management system. An adapter that uses Message Types to parse incoming message data will define Regex fields to describe the data pattern to match, and a corresponding mapping which describes the attribute expressions to store the data. Each segment in the Regex field corresponds to one line in the Regex Mapping field.
The adapter expects to find data in the defined pattern for processing; if no match is made, the message is not processed. A number of Message Types, with Regex mappings, have to be created to address each and every format or combination of data that the implementation will need to handle.
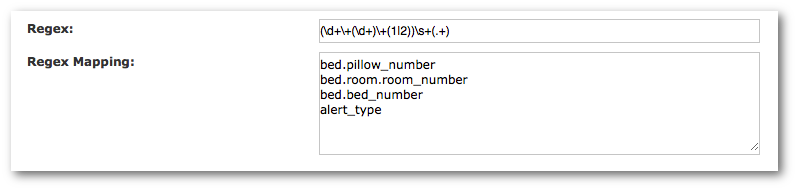
In this example, the Regex (\d+\+(\d+)\+(1|2))\s+(.+) maps to the following attribute expressions:
- bed.pillow_number
- bed.room.room_number
- bed.bed_number
- alert_type
This Regex mapping results in stored data, which may be used to display on the user device. The Regex (\d+\+(\d+)\+(1|2))\s+(.+) may result in a user's device displaying "100:103:1 Code Blue" due to the stored data captured by the following segments.
- "100" is stored by the first segment and mapping, and is the pillow number.
- "103" is stored by the second segment and mapping, and is the room number.
- "1" is stored by the third segment and mapping, and is the bed number. Bed numbers depend on how many beds are in the room.
- "Code Blue" is stored by the fourth segment and mapping, and is the alert type triggered. Alerts are preconfigured to cover conditions ranging from "Code Blue" to "Patient needs water" in a clinical setting.
Literal Expressions Explanation
Regex provides a method of pattern matching where the system expects to find the designated characters in a particular position in the incoming message data. Regex is written in a formal language that can be interpreted by a regular expression processor, which is a program that either serves as a parser generator or examines text and identifies parts that match the provided specification.
Regular expressions have a syntax in which a few characters are special constructs, called metacharacters, and the rest are ordinary. An ordinary character matches that same character and nothing else. The metacharacters are reserved for special search terms and to use one of them as a literal in a Regex, it must be escaped with a backslash (\) character.
There are 11 special or metacharacters: the opening square bracket [, the backslash \, the caret ^, the dollar sign $, the period or dot ., the vertical bar or pipe symbol |, the question mark ?, the asterisk or star *, the plus sign +, the opening round bracket (and the closing round bracket). Any two regular expressions can be concatenated.
The Regex example (\d+\+(\d+)\+(1|2))\s+(.+) is described by its concatenated segments:
- The (\d+\ segment matches the bed.pillow_number mapping, which stores digits in the message data that pertain to the pillow number of the patient.
- The (\d+)\+ segment matches the bed.room.room_number mapping, which stores digits in the message data that pertain to the room number of the patient.
- The (1|2)) segment matches the bed.bed_number mapping, which stores digits 1 or 2 in the message data to associate the alert to bed one or two in that room.
- The \s+ tells Vocera Platform to expect any number of spaces after the group, but there must be at least one space.
- The (.+) segment matches the alert_type mapping. This segment catches any other information that is not recognized by the rest of the string.
Statements of Equality
Statements of equality are an alternative way to specify Regex mappings. In a statement of equality mapping, the left-hand side of the equality statement is the attribute path, while the right-hand side is the value of the attribute path. The right-hand side should use numbered captured groups (e.g., $1) to reference elements matched, but may also include literal strings. When any item contains an equals sign, then every item is expected to be a statement of equality. If the item is not formatted as a statement of equality (i.e., no equals sign or more than one attribute path or value), then an error message will be written to the audit log indicating that the processing failed for this message type.
In this example, the Regex ((\w+):(\w+))\s+(.+) maps to the following attribute expressions:
- bed.room.facility.name
- bed.pillow_number
- bed.room.room_number
- bed.bed_number
-
alert_type

This Regex mapping represents how the information is sent to Vocera Platform by NaviCare. Using the mapping of ((\w+):(\w+))\s+(.+) the information comes to Vocera Platform as General301:1 Code Blue.
A diagram of the expression is: ((\w+):(\w+))\s+(.+)
Pillow Number is equal to bed.pillow_number=$1
Room Number is equal to bed.room.room_number=$2
Bed Number is equal to bed.bed_number=$3
Alert Type is equal to alert_type=$4
- "General" is the name of the facility. In the example above General has been hardcoded into the mapping. The string from NaviCare must include General or the message will not be parsed correctly by Vocera Platform.
-
The first section of the mapping is the group ((\w+):(\w+)) and represents the Pillow Number. The Pillow Number is derived by taking the Room Number and the Bed Number and seperating them with a colon ":". Using the example above, the Pillow number is 301:1
- Contained within the group of ((\w+):(\w+)), the first segment is (\w+) which is the Room Number. The example above tells Vocera Platform that the room number is 301.
- The colon ":" is used to separate the Room Number from the Bed Number.
- The second part of the group is located after the colon ":" and is (\w+) which is the Bed Number. The example above tells Vocera Platform that the bed number is 1. Bed numbers depend on how many beds are in the room.
- The \s+ tells Vocera Platform to expect any number of spaces after the group, but there must be at least one space.
- The final segment of the mapping is (.+). This tells Vocera Platform to expect any number of charcters, but there must be at least one character. This is the alert type that is triggered. In our example, the alert type is Code Blue. Alerts are preconfigured to cover the clinical conditions needed by the facility.
Statements of Equality Explanation
Regex provides a method of pattern matching where the system expects to find the designated characters in a particular position in the incoming message data. Regex is written in a formal language that can be interpreted by a regular expression processor, which is a program that either serves as a parser generator or examines text and identifies parts that match the provided specification.
Regular expressions have a syntax in which a few characters are special constructs, called metacharacters, and the rest are ordinary. An ordinary character matches that same character and nothing else. The metacharacters are reserved for special search terms and to use one of them as a literal in a Regex, it must be escaped with a backslash (\) character.
There are 11 special or metacharacters: the opening square bracket [, the backslash \, the caret ^, the dollar sign $, the period or dot ., the vertical bar or pipe symbol |, the question mark ?, the asterisk or star *, the plus sign +, the opening round bracket (and the closing round bracket). Any two regular expressions can be concatenated.
The Regex example ((\w+):(\w+))\s+(.+) is described by its concatenated segments:
- The ((\w+):(\w+)) segment matches the bed.pillow_number=$1 mapping, which stores the Room Number:Bed Number.
- The (\w+) segment matches the bed.room.room_number=$2 mapping, which stores digits in the message data that pertain to the room number of the patient.
- The (\w+) segment matches the bed.bed_number=$3 mapping, which stores digits in the message data to associate the alert to bed number one or two in that room.
- The (.+) segment matches the alert_type=$4 mapping. This segment stores the alert type information. In our example, the alert type is Code Blue. Alerts are preconfigured to cover the clinical conditions needed by the facility.
Global Variables
A Global Variable represents a capture group that has a fixed set of modifiers. These variables define ways to transform and format data that is stored in the Vocera Platform appliance.
Vocera Platform has created two global variables; now which evaluates to the current time of the systems time zone, and today which evaluates to the current date. To utilize these variables, select a modifier from the list below.
To format these variables, the modifer must be to the right side of the global variable. For example, selecting the global variable of now will add the current time of the system time zone. To format that time as HH:mm, use the modifier of as_mil_time. The full global variable is: #{now.as_mil_time}.
The modifiers below are also defined and may be used to format or augment the base value of the date/time group, now by adding ".modifier", for example #{now.as_mil_time}.
| Modifier | Definition |
|---|---|
| as_date | The date portion of a date/time returned in the format MM/DD/YYYY. |
| as_iso | A time formatted using ISO8601. The format is YYYY-MM-DD'T'hh:mm:ss.sssTZD |
| as_iso_date | The date portion of a date/time using ISO8601. The format is YYYY-MM-DD. |
| as_mil_time | The time portion of a date/time in the form 'HH:mm' (where HH is 0-23). |
| as_mil_time_sec | The time portion of a date/time in the form 'HH:mm:ss' (where HH is 0-23). |
| as_time | The time portion of a date/time in the form 'hh:mm AM/PM' |
| as_time_sec | The time portion of a date/time in the form 'hh:mm:ss AM/PM'. |
| as_weekday | Returns the name of the week part of a date. |
| with_increment | Returns the succeeding day of the value being modified; may be used multiple times. |
| with_decrement | Returns the preceding day of the value being modified; may be used multiple times. |
Only a subset of the above modifers may be used to format or augment the base value of the date group, {today} by adding ".modifier", for example #{today.as_date}.
| Modifier | Definition |
|---|---|
| as_date | The date portion of a date/time returned in the format MM/DD/YYYY. |
| as_iso_date | The date portion of a date/time using ISO8601. The format is YYYY-MM-DD. |
| as_weekday | Returns the name of the week part of a date. |
| with_increment | Returns the succeeding day of the value being modified; may be used multiple times. |
| with_decrement | Returns the preceding day of the value being modified; may be used multiple times. |
Global Variables Example
The global variables and modifiers that are defined above are used to store a date, time, or date and time stamp on any alert. The following example shows how to use the literal expression, the statement of equality, and the global variables.
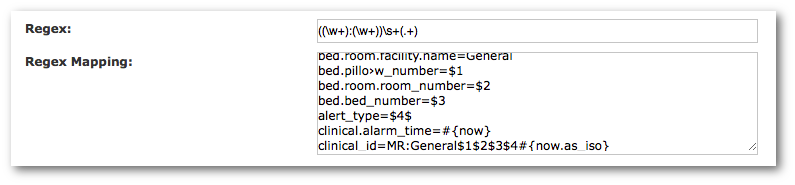
The Regex example ((\w+):(\w+))\s+(.+) maps to the following attributes:
- bed.room.facility.name
- bed.pillow_number
- bed.room.room_number
- bed.bed_number
- alert_type
- clinical.alarm_time
- clinical_id
This Regex mapping represents how the information is sent to Vocera Platform by the vendor. Using the mapping of ((\w+):(\w+))\s+(.+), the information comes to Vocera Platform as General301:1 Code Blue.
- "General" is the name of the facility. In the example above General has been hardcoded into the mapping. The string from the vendor must include General or the message will not be parsed correctly by Vocera Platform.
- The first section of the mapping is the group ((\w+):(\w+)) and represents the Pillow Number. The Pillow Number is derived by taking the Room Number and the Bed Number and seperating them with a colon. Using the example above, the Pillow number is 301:1.
- Contained within the group of ((\w+):(\w+)), the first section is (\w+) which is the Room Number. The example above tells Vocera Platform that the room number is 301.
- The ":" is used to separate the Room Number from the Bed Number.
- The second part of the group is located after the ":" and is (\w+) which is the Bed Number. The example above tells Vocera Platform that the bed number is 1. Bed numbers depend on how many beds are in the room.
- The \s+ tells Vocera Platform to expect any number of spaces after the group, but there must be at least one space.
- The next piece to the mapping is (.+). This tells Vocera Platform to expect any number of charcters, but there must be at least one character. This is the alert type that is triggered. In our example the alert type is Code Blue. Alerts are preconfigured to cover conditions ranging from "Code Blue" to "Patient needs water" in a clinical setting.
- The \s+ tells Vocera Platform to expect any number of spaces after the alert, but there must be at least one space.
- The clincial.alarm_time will store the time the alert was received by Vocera Platform, according to the time zone set in the appliance.
- The clinical.id will store the type of device from which the alert was received, (MR), the name of the facility, (General), all of the alert information, ($1$2$3$4), and transform the time to a date/time formatted using ISO8601, (#{now.as_iso}).
Regular Expression Quick Reference
Use the following list of Regular Expression operators to help create useful mappings in a Vocera Platform implementation.
Regular Expressions Anchors
| ^ | Start of string, or start of line in multi-line pattern |
| \A | Start of string |
| $ | End of string, or end of line in multi-line pattern |
| \Z | End of string |
| \b | Word boundary |
| \B | Not word boundary |
| \< | Start of word |
| \> | End of word |
Regular Expressions Character Classes
| \c | Control character |
| \s | White space |
| \S | Not white space |
| \d | Digit |
| \D | Not digit |
| \w | Word |
| \W | Not word |
| \x | Hexadecimal digit |
| \O | Octal digit |
Regular Expressions POSIX
| [:upper:] | Upper case letters |
| [:lower:] | Lower case letters |
| [:alpha:] | All letters |
| [:alnum:] | Digits and letters |
| [:digit:] | Digits |
| [:xdigit:] | Hexadecimal digits |
| [:punct:] | Punctuation |
| [:blank:] | Space and tab |
| [:space:] | Blank characters |
| [:cntrl:] | Control characters |
| [:graph:] | Printed characters |
| [:print:] | Printed characters and spaces |
| [:word:] | Digits, letters and underscore |
Regular Expressions Assertions
| ?= | Lookahead assertion |
| ?! | Negative lookahead |
| ?<= | Lookbehind assertion |
| ?!= or ?<! | Negative lookbehind |
| ?> | Once-only Subexpression |
| ?() | Condition [if then] |
| ?()| | Condition [if then else] |
| ?# | Comment |
Regular Expressions Quantifiers
Add a ? to a quantifier to make it ungreedy.
| * | 0 or more |
| + | 1 or more |
| ? | 0 or 1 |
| {3} | Exactly 3 |
| {3,} | 3 or more |
| {3,5} | 3, 4 or 5 |
Regular Expressions Escape Sequences
"Escaping" is a way of treating characters which have a special meaning in regular expressions literally, rather than as special characters.
| \ | Escape following character |
| \Q | Begin literal sequence |
| \E | End literal sequence |
Regular Expression Common Metacharacters
The escape character is usually the backslash - \.
| ^ | [ | . |
| $ | { | * |
| ( | \ | + |
| ) | | | ? |
| < | > |
Regular Expressions Special Characters
| \n | New line |
| \r | Carriage return |
| \t | Tab |
| \v | Vertical tab |
| \f | Form feed |
| \xxx | Octal character xxx |
| \xhh | Hex character hh |
Regular Expressions Groups and Ranges
Ranges are inclusive.
| . | Any character except new line (\n) |
| (a|b) | a or b |
| (...) | Group |
| (?:...) | Passive (non-capturing) group |
| [abc] | Range (a or b or c) |
| [^abc] | Not a or b or c |
| [a-q] | Letter from a to q |
| [A-Q] | Upper case letter from A to Q |
| [0-7] | Digit from 0 to 7 |
| \n | nth group/subpattern |
Regular Expressions Pattern Modifiers
| g | Global match |
| i | Case-insensitive |
| m | Multiple lines |
| s | Treat string as single line |
| x | Allow comments and white space in pattern |
| e | Evaluate replacement |
| U | Ungreedy pattern |
Regular Expressions String Replacement
Some Regex implementations use \ instead of $.
| $n | nth non-passive group |
| $2 | "xyz" in /^(abc(xyz))$/ |
| $1 | "xyz" in /^(?:abc)(xyz)$/ |
| $` | Before matched string |
| $' | After matched string |
| $+ | Last matched string |
| $& | Entire matched string |
Ruby Editor Reference
Use the Ruby Regular Expression Editor for troubleshooting: http://rubular.com/
Conclusion
This concludes the discussion of Regular Expressions that may be used in a Vocera Platform implementation.